No ‘I’ in Molecule: the Chemical Teamwork behind the Origin of Life
Before even the most basic cell-like life could develop, molecules had to transition from the simple building blocks found on the early Earth (compounds like methane, ammonia and water) into the complex, self-replicating polymers that our bodies use to store information and catalyse (or ‘speed up’) the processes necessary for us to live. These molecules are the ubiquitous biopolymers that we learn about in high school: DNA and RNA (built from nucleotides and used to encode genetic information), and proteins (made up of amino acids; the ‘workhorses’ of the cell).
In a landmark experiment in the 1950s, American chemists Stanley Miller and Harold Urey demonstrated that amino acids could be generated from a mixture of simple chemicals, similar to those which may have been found on the early Earth1. More recently, groups like that of John Sutherland in Cambridge have shown that nucleotides can be made from equally uncomplicated molecules, such as hydrogen cyanide2. In fact, multiple teams of scientists around the world have demonstrated that the amino acids and nucleotides necessary for constructing the biopolymers of life can be formed pretty readily from very basic chemicals that were likely available in a pre-life environment.
However, no one really knows exactly what the Earth looked like 3.8 to 4 billion years ago, and that is a sticking point. Whilst much thought and effort have been put into designing these experiments in a plausible manner, the chemist’s stereotypical round-bottomed flask is a far cry from a primordial ocean full of undetermined salts and dissolved minerals, or even a primordial puddle. Trying to reverse engineer how our biology developed using only the reactions we can perform in a laboratory is difficult, and so our thinking must be a little more abstract – we need to consider a simplified version of interactions and reactions between the molecules that built up our biochemistry.
Enter science’s favourite tool: mathematical modelling.
The big strength of mathematical modelling here is the simplification of complex chemical systems, requiring relatively little biochemical knowledge, in order to gain some understanding of the key processes occurring. Very useful for a field that cannot definitively state which chemicals or reactions were involved in the phenomenon it investigates. Three separate, and still influential, theories have been proposed (all in 1971) to mathematically model the earliest living systems and to help us understand how they developed from ‘dead’ chemicals: Tibor Ganti’s Chemoton model, the Hypercycle from Nobel Prize laureate Manfred Eigen, and Stuart Kauffman’s Autocatalytic Set Theory.
All of these models rely, at least in part, on a phenomenon known as autocatalysis. This is the ability of a molecule to catalyse its own formation from a precursor molecule or molecules. However, the term can also be applied to instances where molecules catalyse each other’s synthesis, forming a web of precursor and product molecules. This then reinforces each molecule’s formation and helps ‘outcompete’ other reactions that aren’t included in the web. The favoured formation of ‘web’ molecules that arises is sometimes called ‘selection through replication’. It is thought that such a selective process is what allowed early life to evolve from primordial soups.
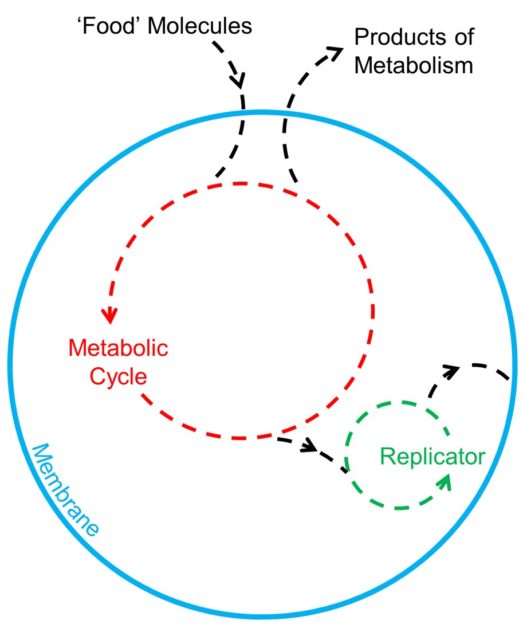
The Chemoton model3 comprises three of these autocatalytic webs of molecules, which are intertwined with each other to act as a model for primitive cell-like life. The model is built around a self-replicating RNA molecule contained by a membrane and chemically ‘wired’ to the membrane and the outside world by a basic metabolism, which moves the building blocks for the self-replicating system into the cell through the membrane. Eventually, the replication of the RNA and growth of the membrane allow the cell to split, replicating the entire parent cell to form two identical daughter cells.
Unfortunately, although it is a strong model for simulating a simple cell, the Chemoton doesn’t really explain the mechanism of how these systems developed. Instead, it is limited more to questions like: did genetics (replicating strands of DNA and RNA) or metabolism develop first? Whilst this is important and interesting, it is not the concern here.
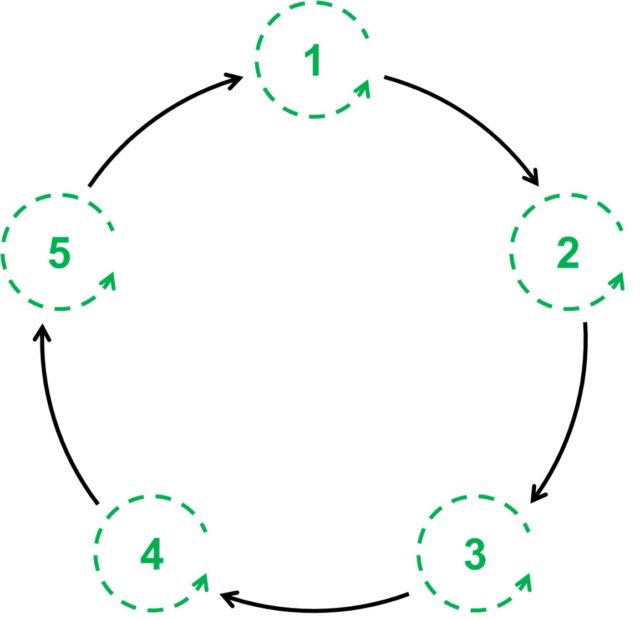
The hypercycle4 does slightly better with explaining the development of the complex molecules of life. It is a cycle of reactions that is arranged so that the product molecule of a given reaction in the cycle catalyses the formation of the next molecule in sequence. However, each molecule also catalyses the formation of itself. So once a molecule is made, it speeds up the generation of the next molecule as well as itself, allowing for an explosion in the amount of each replicating molecule in the hypercycle over a relatively short time-frame. Both the system as a whole and each individual molecule is autocatalytic.
This model takes a step back from the Chemoton, showing how an autocatalytic network can compete with other reactions in the same system, with the most efficient network emerging as the ‘winner’. This can then go on to form a truly living system. However, hypercycles only work for biopolymers that replicate in the same way as DNA or RNA – through a matching of the building blocks in a chain to build a ‘negative’ biopolymer that can then be used as a template to rebuild the molecule, which is essentially identical to the original ‘positive’.
For a model of the origin of life not constrained to any particular chemistry, we must turn to autocatalytic sets. By removing the requirement for life to have the same chemical form as it does on Earth, autocatalytic sets could just as readily describe the development of life here as they could life on Europa, or any potentially habitable planet, moon or cosmic rock.
An autocatalytic set5 is essentially another network of reactions, with input food molecules that are assumed to be readily available from the environment and product molecules that are formed from the input molecules (and maybe from some other product molecules). All molecules, product or input, are linked together through reactions to make up the network. The only additional constraint is that each product molecule has to catalyse another reaction in the network.
In practice, this means that as soon as one reaction in the network has turned food molecules into product molecules, there is a catalyst present for one of the other reactions in the network, which will now proceed more readily once all the reagents needed are available. Some of these may be food molecules and some may be other product molecules, which can affect the initial growth of the network. As more of the reactions in the network proceed for the first time, more and more catalysts are formed. This increases the likelihood of any given reaction being catalysed. Over time, the network is fully built up to the point where all the catalysts involved are being produced, and this cross catalysis reinforces the network as a whole – allowing it to outcompete other chemical reactions.
The general applicability beyond a particular chemical system is the real power of autocatalytic sets. Kauffman has noted that such replicating behaviours could be expected in a whole range of different chemistries – not just those familiar to us from our own biology. Given the number of possible worlds in the cosmos, reproducing molecules that may be a precursor of true life might potentially be found throughout the universe.
Whilst dreaming of finding alien biopolymers is a good way to get yourself up in the morning, it’s important to note that none of these three models have yet been experimentally validated. These replicating systems are likely to be very complex, and trying to unpick exactly how they work may prove difficult. However, It seems clear that at its most fundamental level, life requires cooperation between networks of molecules to emerge. Quite the heartening thought.
This article was specialist edited by Miriam Scarpa and copy-edited by Heather Mackie.
Author
References
- https://www.newscientist.com/article/mg23831820-400-the-epic-hunt-for-the-place-on-earth-where-life-started/
- https://www.sciencemag.org/news/2015/03/researchers-may-have-solved-origin-life-conundrum
- http://wasdarwinwrong.com/korthof66.htm#chemoton
- Eigen, M. and Schuster, P., J. Mol. Evol., 1982, 19(1), pp.47-61 (Paywall)
- Kauffman, S. A., Life, 2011, 1(1), pp.34-48 (Open Access)