
Robots, Computers and Hard drives: The age of DNA?

Humanity has a problem with the volume of information we are producing, in the last two years alone we produced more data than we have before in all of human history 1. From late night tweets to academic papers, this information needs to be stored somewhere and a rather surprising solution may be found within our own biology.
DNA is in every living organism on earth, storing the genetic code that makes a giraffe a giraffe and an apple tree an apple tree. Every skin and muscle cell contains all the genes required to make each organ and tissue within that organism. To understand how DNA can be encoded into information, we need to know about its structure first. DNA is a long chained molecule formed of four bases – adenine (A), guanine (G), thymine (T), and cytosine (C). It’s sister molecule RNA has uracil (U) instead of thymine. A polynucleotide or single strand of DNA then pairs up with a complementary strand to form the classic double helix structure. The bases in a chain essentially spell out a code that, when read by an cell, can be converted into RNA. These RNA molecules are then used as a recipe for specific proteins involved in making our cells exist both structurally and functionally. These regions of DNA that are converted into proteins are what we refer to when we say genes. This structure has several properties that make it useful for storing biological information, and why we might look to DNA to store big data.
Firstly, DNA’s double helix structure makes it very resistant to damage. This is thanks to various chemical bonds that allow the structure to remain stable when not in use. Cytosine can degrade into Uracil, however DNA naturally lacks Uracil bases meaning this degradation is more easily noticed by the cell and can be repaired. This creates a structural advantage over RNA, allowing DNA to become more prevalent and leading to the development of more complex life 2. DNA is also very easy to store in limited space, with a capacity to store 215 petabytes (or 10,00,000 gigabytes) of information in one gram of DNA, it’s easy to understand how a tiny skin cell contains all the necessary information to make you. This can be attributed to two traits; that bases are individually very small so a lot of information can be stored in very little DNA, and DNA’s ability to be folded and condensed easily, making it even easier to store 3. Finally, and what makes DNA especially attractive as a method of storing data, is the natural mechanisms of life which work against data corruption and allow for easy replication 4. Living organisms naturally want to prevent their genes from mutating and want exact copies to be produced during replication. Mutations in the genome of an organism could result in defunct genes or worse, even the development of cancer. Evolutionary pressure, combined with millions of years of practice, have produced mechanisms in each and every cell to prevent this corruption of information generations ahead of what keeps your hard-drive from losing the essays and lecture notes you have stored on it.
If DNA is so well suited to this role why haven’t we used it before? DNA data storage is a relatively new idea and only in the past half-decade has any real progress been made in its advancement. It was only in 2013, where DNA was shown to allow partial data retrieval, and in 2015 where full data recovery was shown to be possible. However, neither of these methods approached the Shannon Information capacity (SIC) that DNA was theorized to have. The SIC simply shows how much information you can send via a method of communication, for example the SIC of a tweet would be 140 characters. This means that the volume of data that was stored in each of these methods was far below the maximum capacity DNA is believed to have 5.
What’s changed now is that that a new way of storing and recovering information from DNA has been developed called DNA Fountain. This has meant that we are now able to realistically look at DNA as a method of data storage because DNA Fountain now allows full recovery of information while reaching the SIC of DNA. We can finally make use of all the space DNA has to store information and get it back out again without mistakes. It does this by two main steps, first the data that is being uploaded is converted into its representation in binary, for example the letter A is represented with 01100001. This code is then converted into DNA base pairs with base pairs representing a section of the code. Adenine represents 00, Cytosine represents 01, Guanine 10 and Thymine 11, meaning the original code of 01100001 for the letter A would become CGAC when it is stored in DNA. As you can see, the final document can be quite large and this is where we run into another problem with DNA. Base pairs that represent code could accidently form regions in the new strand of DNA that cause structural weakness, these include regions high in CG pairs and homopolymer regions which can be difficult to read. The final conversion is scanned to remove these potentially dangerous base pairs and a new configuration of the uploaded information is synthesised. 6.
The second step is where the truly innovative part of this method comes in; taking advantage of the Fountain Method, a process of transferring information which splits the original upload into packets. As these packets are random functions of the original file, once a volume of information slightly larger than the original file is uploaded you can guarantee complete transfer of the original file with no errors 7.
With the advent of DNA Fountain, taking advantage of DNA to store data is a very real possibility, but does this mean that DNA computers could also be a thing of the not too distant future? In short, no. DNA, while a great medium to store information, has an incredibly slow processing speed 8. Simple equations that would be measured in fractions of a second even on outdated hardware would be measured in hours or even days if processed using DNA. While this does not rule out the possibility of biological computers, in fact the first example of a calculation being processed in DNA dates back to 1994 9, it would still mean a great step backwards in processing speeds. What is a possibility however is the development of DNA robots. In 2000, a team designed and produced a DNA robot shaped in the form of tweezers that could open and close, as can been seen from Figure 1 below 10. A simple mechanism like this could one day develop into DNA robots that are able to release drugs within our bodies at targeted sites as part of medical treatments or even destroy damaged cells to prevent cancer.
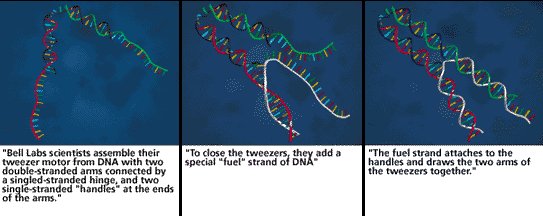
An example of a DNA robot. Credit: Anna Salleh via abc.net.au
DNA Fountain represents a great step forward in biotechnology and an innovation in data communication that is taking advantage of the natural properties of DNA. Resistant to data corruption and easy to store, DNA’s utilisation in computing could mean a greater use of biotech in the future, and while DNA may lack the fast processing speed required to overtake modern computers, innovators are already utilising DNA to build mechanisms on a microscopic scale that would otherwise be impossible.
This article was specialist edited by Alisha Aman and copy edited by Katrina Wesencraft.
Author
References
- Service, R. (2017). DNA could store all of the world’s data in one room, Science Mag.
- Alberts, B., et al. (2002). Molecular Biology of the Cell. New York, Garland Science: 953-959.
- Service, R. (2017). DNA could store all of the world’s data in one room, Science Mag.
- Erlich, Y. and D. Zielinski (2017). DNA Fountain enables a robust and efficient storage architecture, Science. 355: 950-954.
- Erlich, Y. and D. Zielinski (2017). DNA Fountain enables a robust and efficient storage architecture, Science. 355: 950-954.
- Erlich, Y. and D. Zielinski (2017). DNA Fountain enables a robust and efficient storage architecture, Science. 355: 950-954.
- MacKay, D. J. C. (2005). Fountain Codes, IEE Proceedings – Communications. 152: 1062 – 1068.
- Kwiatkowska, M. (2015). Organic ‘computers’ made of DNA could process data inside our bodies, Phys Org.
- Kwiatkowska, M. (2015). Organic ‘computers’ made of DNA could process data inside our bodies, Phys Org.
- Yurke, B., et al. (2000). A DNA-fuelled molecular machine made of DNA, Nature. 406: 605-608










1 Response
[…] post Robots, Computers and Hard drives: The age of DNA? appeared first on […]