


Artificial intelligence (AI) and machine learning are amazing tools and valuable assets to businesses and laboratories worldwide. As a microscopist, I’ve used image analysis tools, like Trainable Weka1, that use machine learning. These tools make it remarkably easy to segment images and save time trawling through datasets. Some advanced image analysis tools use neural networks – algorithms that are designed to work in a similar way to the brain (at least conceptually speaking). These algorithms have the abilities and plasticity required to learn and change behaviours based on ground truth and have countless useful applications. From my own experience, I’ve realised that with adequate training, these tools can separate cellular structures within images just as well as a human can (and in some cases, even better).
So why am I worried about it?
Turns out, machine learning isn’t just good at analysing data – it’s also pretty good at manipulating it. Assuming you haven’t been living under a rock, you’ll remember the 2019 internet craze of FaceApp. Using neural network-based AI, this novelty app could make you look older or younger, and even show you what you would look like as the opposite sex – with scarily believable results in some cases. For a short time, the app even had features to make you “hotter”, although this was swiftly removed due to racial discrimination2. The app was entertaining and I used it extensively myself, although it quickly lost its novelty factor.
What has followed, however, has been interesting. This approach has been used to create ‘Deepfakes’ – convincing computer generated images and video clips based on real faces and voices. Deepfakes are everywhere, you only need to type that word into Google or YouTube and you will be assaulted with a barrage of fake videos featuring celebrities and politicians – all built from sophisticated neural networks. Alarmingly, there have even been several instances of Deepfake porn using celebrity faces.
What these things all have in common is that they change data rather than completely making it up. Making you look older is easy enough and with enough images and audio clips of someone’s face and voice you can then make them perform fake speeches. The data is believable because it’s based on ground truth.
However, what happens when AI becomes so smart that it can completely make up believable images? I first learned about this while at a talk given by Dr. Péter Horváth – a multidisciplinary computational cell biologist from the Institute of Molecular Medicine Finland3.
As part of his presentation, Dr Horváth showed us one of the problems faced in image processing: the lack of readily available datasets to train machine learning tools. Vast datasets are required to train the algorithms and this data isn’t always accessible. For example, if you want to teach a computer how to identify tumour cells, you need to show it lots of examples of what a tumour cell looks like. However, patient data like this is fiercely protected and difficult to obtain. We can’t possibly hope to use artificial intelligence to identify damaged cells if the programme has never seen one before.
To overcome this, Réka Hollandi from the Horváth group took the limited data available and used image style transfer – a fancy technique – to produce super realistic images that are completely separate from the training data4. It’s a bit like me showing you some pictures of Dalmatians, then asking you to draw a Dalmatian from memory. Yes, I’ve trained you with some prior knowledge, but the Dalmatian you draw will be completely unique. Now imagine that I did the same with a computer – and the picture it drew looked exactly like a real photo of a never-before-seen Dalmatian. That’s what this technique achieves but with microscopy pictures of cells.

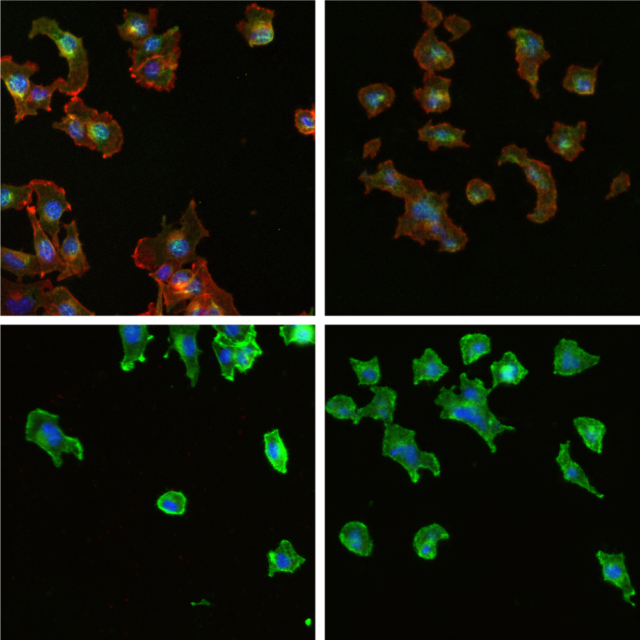
When these augmented computer-generated images were shown to pathologists, they were largely unable to tell the difference between them and the real data. By generating these training sets, the information gap between academics and clinicians is bridged – all without violating patient data protection. A great innovation, with practical applications for the medical community.
Though ever being the cynic, I don’t see it that way. What Réka Hollandi has achieved is to be praised – let’s be clear on that – but I worry what this kind of software may be used to achieve among the rogue scientists in the community. All too often, papers are retracted when someone notices that they contain manipulated data – but usually the authors try to do this in Photoshop (and god forbid, some of it looks like it was done in MS Paint). But what can we do when these pixel-perfect images are so similar to real data that they slip through the net?
I contacted Péter Horváth and Réka Hollandi to ask them their thoughts about this and they share my concerns. They showed me how easily the data is generated and commented on how researchers with questionable practices could use this to their gain. According to Dr Horváth, big papers like Nature will have their own filters to spot fakes – but he seriously doubts they would be able to pick up data generated in this way.
With technology like this, rogue scientists could produce a manuscript with realistic images without ever even having to set foot in the lab. Up until now, data manipulation usually occurred when the results just weren’t good enough, or when they didn’t fit the hypothesis in mind. Data was changed – not created.
Sadly, this is something we are going to need to prepare for. As analysing data gets easier, so does fabricating it. Hopefully scientific magazines can train their own networks to spot fake images and can stay a step or two ahead in the cat and mouse game. People will always find a way to cheat – so remain critical and challenge data you don’t think looks right. In this post-truth era, seeing isn’t always believing.
This article was specialist edited by Natasha Padfield and copy-edited by Vaiva Gikaite.
Special thanks to Péter Horváth and Réka Hollandi from the Synthetic and Systems Biology Unit, Hungarian Academy of Sciences, Biological Research Centre.

